計算機學會通訊編者按:自2016年以來,周伯文教授及其團隊持續深入研究agi的實現路徑;當前,面對大語言模型在scaling law與架構等方面的技術瓶頸,周教授及其團隊不僅提出了完整的agi實現路徑,更創新性地從應用價值出發,探索更高效發揮agi潛力的場景與方法。
本文詳細介紹了這一原創性路徑及其技術研究,為agi的未來發展提供新的縱深視角與實踐參考。
人工智能突破從哪里來,
未來向何處發展?
前沿學者們對大語言模型的能力邊界進行了持續討論。例如,圖靈獎得主yann lecun常提及,機器學習目前存在諸多短板,他的研究偏重泛化性,關注如何盡量達到人類的智能。而deepmind強化學習團隊負責人david silver提到,要做到superhuman intelligence(超人類人工智能)以及發現更多新知,大語言模型尚且存在局限,仍有許多工作有待完成。在這里,他強調的是如何在一些專業領域實現superhuman intelligence,并不是具備更強的通用能力。

因此,在當下這一時間節點,探討agi的實現方向及其關鍵問題,具有重要的意義。我最早對agi發展路徑的思考作公開分享是在2016年,當時我正擔任ibm總部的人工智能基礎研究院負責人。在那一年的town hall meeting上,我提出人工智能的發展會經歷三個階段,分別為狹義人工智能(ani)、廣義人工智能(abi),以及通用人工智能(agi)。

周伯文教授在2016年提出,人工智能的發展會經過ani、abi、agi三個階段
當時我的判斷是,基于深度學習的監督算法僅能實現狹義人工智能,因其在任務間的遷移和泛化能力極為有限,并且需要大量標注數據。另一方面,2016年,agi還是非常模糊的愿景,全世界只有極少數研究者談論,我個人當時給出agi的定義是比人類更聰明,會獨立自主學習,并且一定需要更好地治理和監管——這點非常明確。但怎樣從狹義人工智能走向agi,我判斷中間有一個必經階段,并將其稱之為abi,即廣義人工智能。這應該是abi概念被首次提出,因此我也給出了三個必備要素的定義:即自監督學習能力、端到端能力,以及從判別式走向生成式。盡管2016年時狹義人工智能進展明顯,但因為判斷其能力存在上限,我當時呼吁ai研究者盡快從狹義人工智能,轉向探索廣義人工智能。回過頭看2022年底出現的chatgpt,以上三個要素基本都已具備,所以可以認為基于scaling law的大模型較好地實現了廣義人工智能。但當時我本人未曾預料其具備如此強大的涌現與零樣本學習能力,盡管我曾提到abi應該具備優秀的小樣本學習能力。認知決定行動,行動取得結果,有了上述判斷,我的團隊在2016年轉向廣義人工智能研究,開始思考如何讓模型更好地泛化,隨后在2016年底提出了多頭自注意力機制的原型(a structured self-attentive sentence embedding, https://arxiv.org/abs/1703.03130),并首先應用在與下游任務無關的自然語言表征預訓練中。
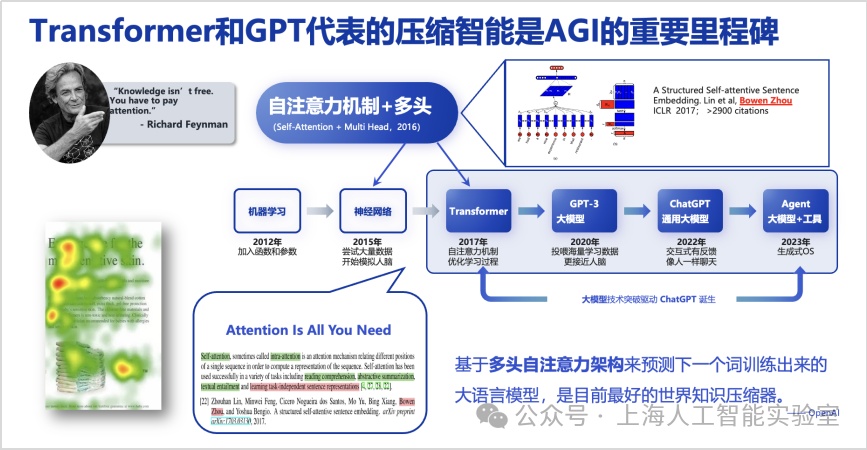
研究團隊認為,模型在思考過程中能更靈活、多樣、有效地使用元動作,是模型在推理階段能夠利用更多思考時間解決更復雜任務的重要原因。transformer完善了多頭自注意力架構,但其價值的放大,來自于openai的研判。openai發現并認為,基于多頭自注意力架構用于預測下一個詞,由此訓練出來的大語言模型是目前最好的世界知識壓縮器。站在2019-2022年的視角,這個認知非常前沿,是實現壓縮智能的基礎。我們可以認為transformer和gpt代表的壓縮智能是agi的重要里程碑。但毫無疑問,僅靠壓縮智能遠遠不能實現agi。google deepmind發表于2023年的論文(levels of agi: operationalizing progress on the path to agi. 2023),將agi進行了分級。一方面借用了我們提出的從狹義人工智能到通用人工智能對比的概念,另外一方面在專業性上將人工智能分成了6個級別,從不具備ai能力即純粹編程,到superhuman level(“超人類”水平)。
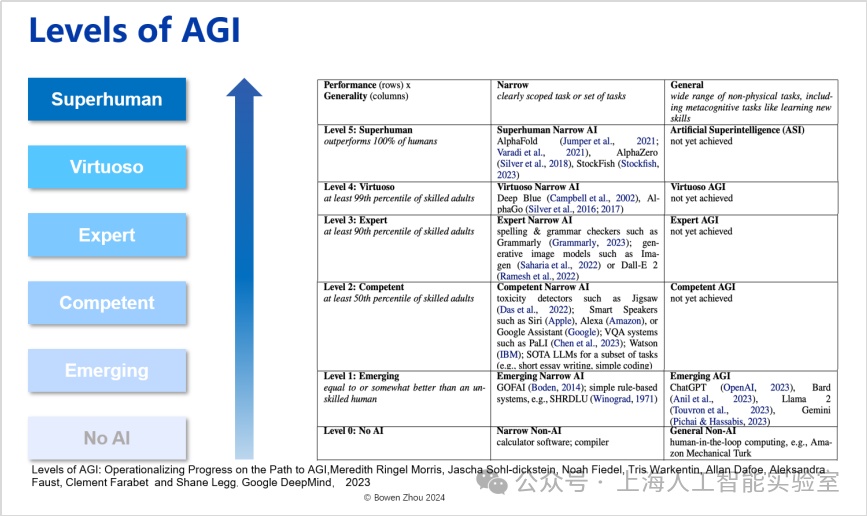
google deepmind把agi分為6個等級
可以看出,chatgpt雖然有很好的泛化性,但在智力水平只屬于第一級emerging level(“初現”),還達不到第二級competent level(“和人類相當”)——后者的定義是超過50%的人類。再往上為expert(專家級),是指超過90%人類的水平;virtuoso(魔術師級)是指超過99%人類;而所謂superhuman(超人類)是指在該領域可以超越所有人類——如同最新版的alphafold一樣,人類無法在蛋白質折疊這個領域再擊敗ai了。
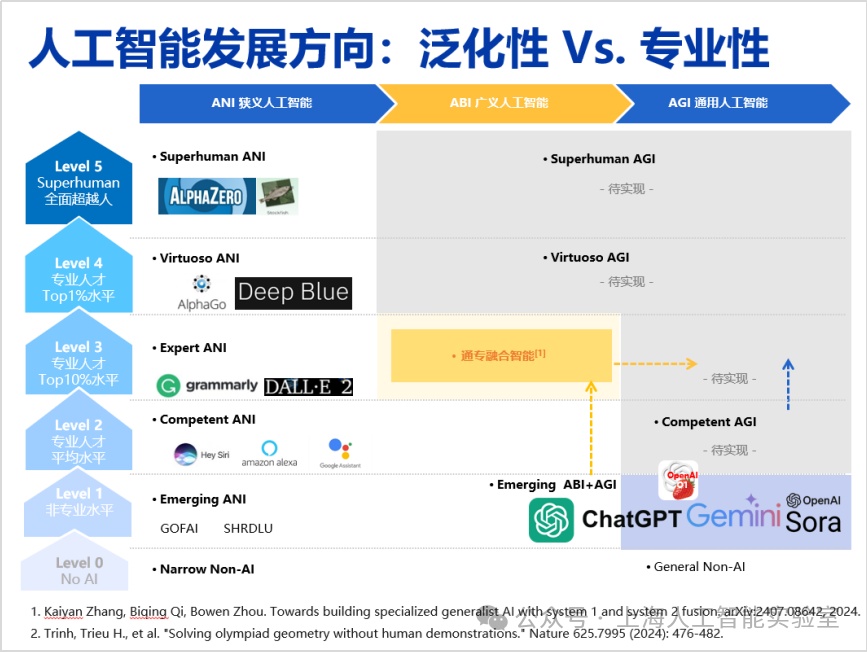
但類似alphafold這種專業性極強的ai,其泛化性往往較為有限。若將泛化性與專業性結合考慮,可以形成一個二維概念框架。我們注意到,chatgpt和sora在泛化性方面取得了顯著進展,但在專業性方面僅達到人類15%-20%的水平。即便運用scaling law(規模律)進一步增加模型參數,其專業性的提升效果并不顯著,而成本卻顯著增加。專業性不足不僅限制了創新,還會導致大量事實錯誤的出現。回顧人工智能七十余年的發展歷程,我認為實現通用人工智能的路徑可被視為一張二維路線圖:橫軸代表專業性,從ibm的深藍到deepmind的alphago,在橫軸方向(專業性)上取得了顯著進展;但這些工作的泛化性一直較為薄弱,限制了ai技術的進一步普及。
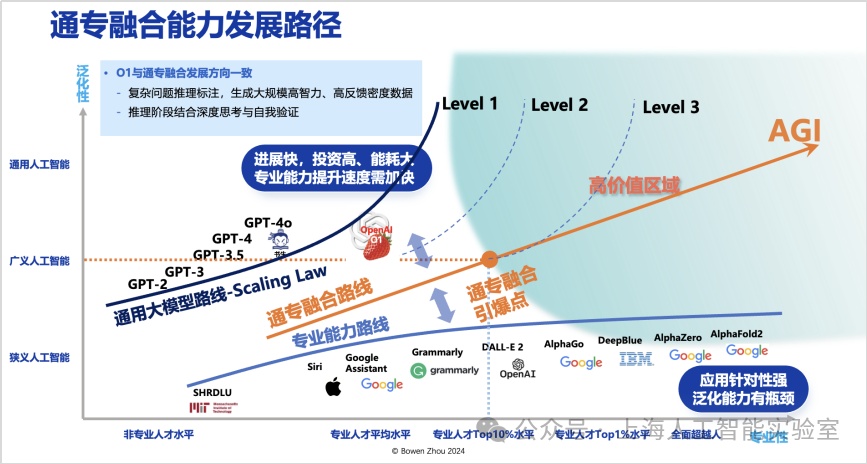
而從2016年多頭自注意力,到transformer、chatgpt出現,壓縮智能代表的是泛化性狂飆。但可以看出,它在專業性上的水平進展極其緩慢,scaling law很明顯不足以延伸它的專業性,能力長期停留在level 1的左側。
未來人工智能應當如何發展,并推動更大的價值創造?從2022年底,我在多個場合講過,存在一個高價值區域,這個區域在橫軸應達到或超過90%以上專業人士的水平。同時又具備能達到廣義人工智能級以上的泛化能力,以極低成本在不同任務之間進行遷移。這個區域,即是agi路線圖中的“高價值區域”。
這個區域離這張路線圖出發最近的點,我稱之為通專融合引爆點。是否存在一種路線,從當前技術出發,能更快地接近通專融合引爆點?我認為存在這樣的路線,并將其稱為通專融合技術路線。
雖然我們看到此前openai一直都是在scaling law的泛化性上持續推動,但今年也開始朝專業性方向迭代。從gpt-4o之后,將很多精力投入“草莓”系統的研究,開始沿著與通專融合相似的方向發展。
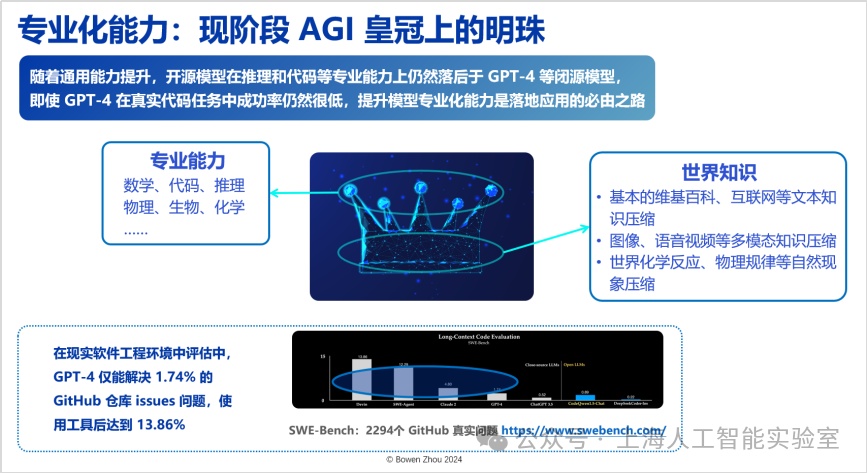
關于通專融合的目標,一方面,隨著合成數據飛輪效應的加速,過去一年基礎模型獲取通用能力的難度顯著降低;另一方面,在世界知識的壓縮能力上,開源模型的性能已無限逼近閉源模型。然而,不管是開源還是閉源模型,在專業化能力方面仍存在顯著瓶頸。例如,在實際的軟件工程環境中,gpt-4僅能解決github中1.74%的人類提出的問題。即便通過引入大量工具、結合基礎模型與工具型agent的方式,這一比例也僅提升至13.85%。
可以看到,目前對于世界知識進行壓縮的智能發展路徑正在自然演進,但我們認為在這之上的專業能力,才是現階段agi皇冠上的明珠。
通專融合agi實現路徑
我們提出的通專融合,不僅需要同時具備專業性和通用泛化性,還必須解決任務可持續性的問題,來讓人工智能能高效地可持續發展,它們形成了通專融合技術挑戰的三個頂點。

“通專融合”必須實現“通用泛化性”“高度專業性”“任務可持續性”三者兼得
自2023年初以來,我們提出了具體的通專融合實現路徑(towards building specialized generalist ai with system 1 and system 2 fusion,https://arxiv.org/abs/2407.08642),該路徑需要三個層次相互依賴,而非僅依靠單一模型或算法。對每一層我們都有整體規劃與具體技術進展,不過由于時間關系不能一一展開,下面簡要描述每一層的核心思想,以此完成對通專融合技術體系的拆解。
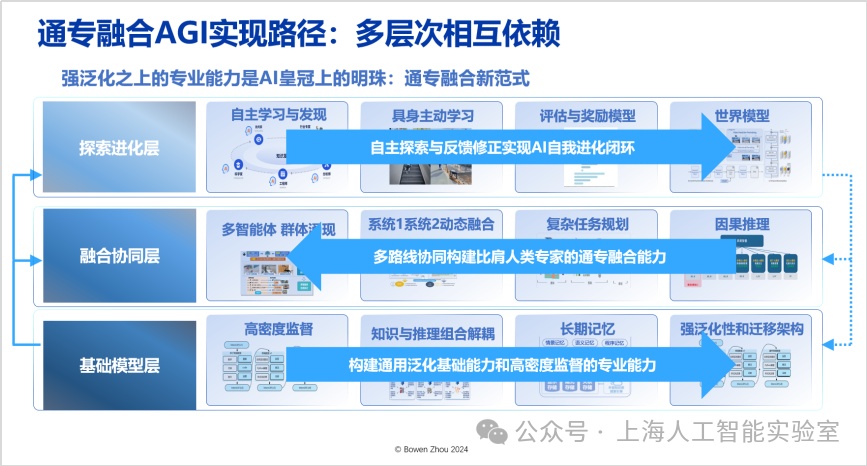
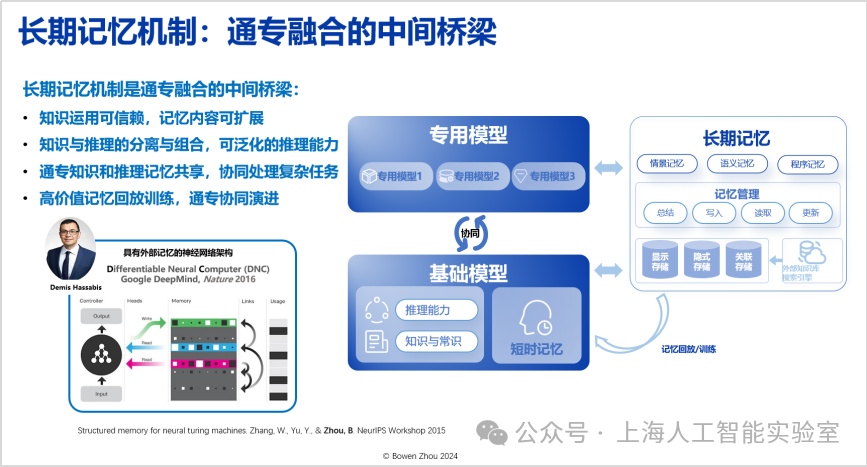
路徑的第一層是“基礎模型層”,這一層需要大量工作來改變現有架構。其中,最重要的是如何實現知識與推理的有效解耦與組合,同時實現高智力密度的監督信號,并在架構方面實現長期記憶——目前transformer難以實現長期記憶,通過改變現有架構,ai能夠獲得強大的泛化性和遷移能力。在基礎模型的能力之上,具備通用的架構和學習能力,還需要高效的學習方法,才能更好地實現通專融合,這便進入了第二層“融合協同層”。自2017年以來,我們提出“系統1”和“系統2”(即“快思考”和“慢思考”)的動態融合,以解決更多問題。兩種思考方式的動態融合最接近人類大腦的思考方式,也是從能耗和泛化角度而言最佳的方法。這里可以進一步延伸至多智能體協同,它不僅僅是單個系統1或系統2,多個智能體的協同在群體層面產生智能涌現,必須具備復雜任務的規劃能力。
在融合協同層,需要脫離目前基于統計相關性的推斷,轉向因果推斷,這是避免大模型能力瓶頸的有效方法。我們已經認識到,“壓縮智能”并不代表所有智能。正如人類看再多的書和視頻也無法學會游泳一樣,要獲得關于游泳的智能,就必須與物理世界互動,讓物理世界的反饋影響肌肉記憶,直至大腦皮層。這種反饋自主學習與發現,就是我們所說的第三層“探索進化層”,這層的關鍵在于高效地獲取反饋和獎勵,即從真實環境中獲得可持續、高置信的反饋信號。同時,我們還需要跨媒介可交互的世界模型來對物理環境進行建模。
通專融合關鍵技術
1、基礎模型層的進化方向
高密度監督信號是專業化知識注入的關鍵。在基礎模型層,必須高效引入高智力密度監督信號。在壓縮智能學習方式下,容易讓人誤以為只需給出下一個詞作為監督,模型就能高效學習。然而,這種學習方式在很多情況下只能讓模型學會一種“快捷方式”(shortcut),它知道如何找到最佳答案,但對于“為什么這是最佳答案”,則缺乏系統化的思考。
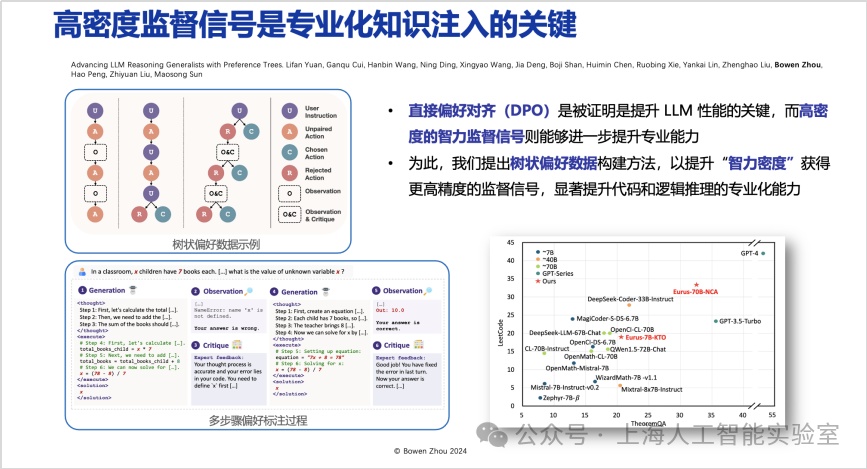
基于這一原因,在直接偏好優化階段,我們提出了帶有觀測、批評、修改循環流程的樹狀偏好數據構建方法。在每個推理階段,給模型提供多個選擇并給出優先級,通過更高密度的監督,使模型在推理過程中學會更多可替代性的比較(advancing llm reasoning generalists with preference trees,https://arxiv.org/abs/2404.02078)。該方法在openai o1亮相前已公布,仔細研究會發現它采用了類似的高智力密度監督推理過程。這是為模型注入專業化知識的關鍵。
何為“專業”與“不專業”?前者意味著始終能在多個選擇中找出最佳答案;而后者則僅能做出“最佳猜測”,常被其他待選項所混淆。(11月25日,上海ai實驗室推出了能夠自主生成高智力密度數據、具備元動作思考能力的強推理模型書生internthinker。該模型能在推理過程中進行自我反思和糾正,從而在數學、代碼、推理謎題等多種復雜推理任務上取得更優結果。)
除了當前的主流結構外,高效的知識推理可組合可分離的架構更有利于構建可信賴、泛化、擴展的大模型。布羅德曼分區(brodmann area)是神經科學里面公認對大腦不同區域承擔不同專業功能的分區架構。我們尋找的架構,應具備知識應用可信賴、推理過程可泛化、知識內容可拓展三種性質,同時能夠有效地進行組合。transformer的一個優點在于,可實現推理與知識的高度融合,擁有很大的提升空間。但缺點也在于當知識和推理高度融合之后,一旦模型產生幻覺,將很難溯源。所以尋找一種新的架構極其重要。
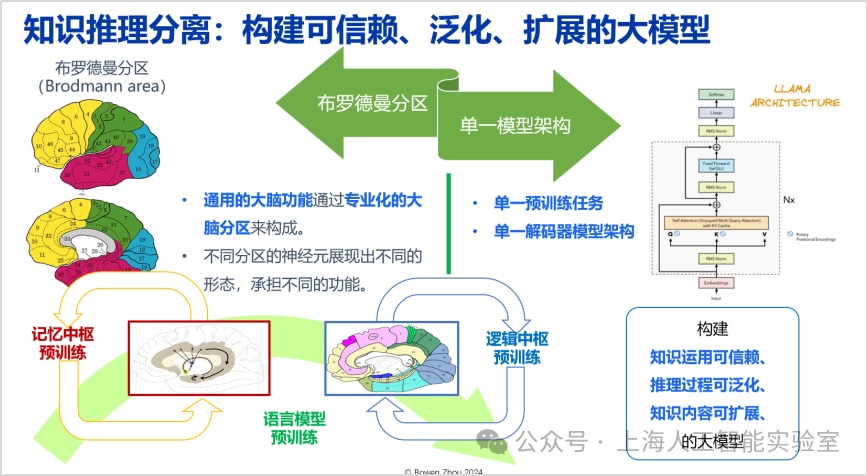
長期記憶機制是通專融合的中間橋梁,需要這樣的機制在通用與專業能力之間架起一座兼容橋梁。目前,這種長期記憶機制在transformer架構中的表現并不充分,這方面我們有一系列工作(如我2015年的研究https://arxiv.org/abs/1510.03931,以及近期的工作https://arxiv.org/html/2408.01970)。
2、融合協同層
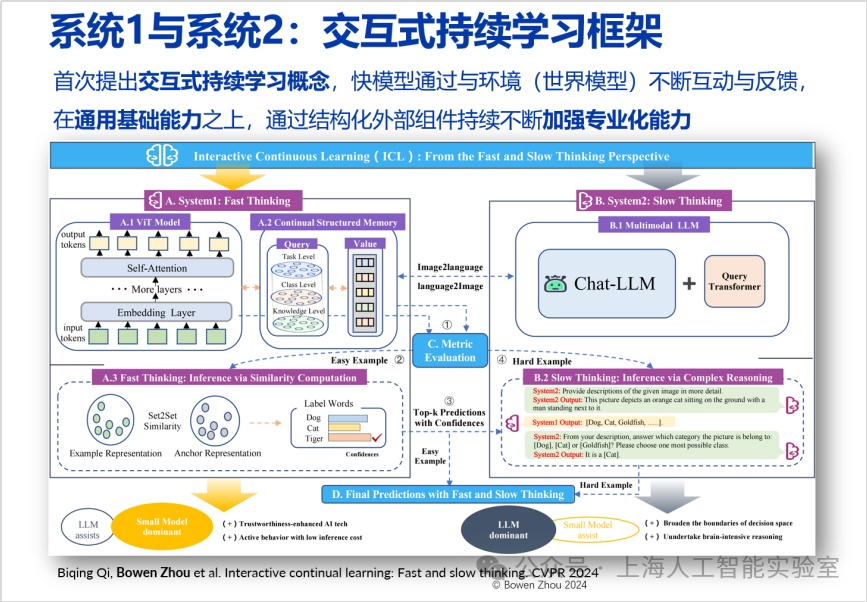
通專融合路徑的第二層是融合協同層,特別強調快速處理和深度推理結合。在cvpr 2024收錄的論文中,我們探索了這一領域(interactive continual learning: fast and slow thinking)。我們構建了一個高效識別圖像的快系統(專用系統),當其遇到不確定的情況時,會將信息傳遞給一個更強大的慢系統(通用推理系統)。慢系統基于輸入信息進行深度分析,并將結果反饋給快系統并在快系統中完成了一個結構化長期存儲的更新。這種結合不僅降低了能耗,還提升了處理速度和準確率。
這種結合在處理速度和能耗上優于單獨使用慢系統。許多問題快系統可自行回答,無需調用慢系統。此外,我們發現這種結合的準確度高于單獨使用快系統或慢系統,這一發現頗具啟發性。其潛力在于,快系統缺乏深度思考,易犯錯;而慢系統對具體情況的判斷不如快系統,許多細節不了解。通過快系統的輸入,慢系統可排除不可能情況,做出更好判斷。
快系統好比前線偵察員,提供具體輸入信息;慢系統則相當于后方指揮官,具有更好的思考深度和判斷能力。兩者結合,可做出更準確高效的決策。這種結合不僅是簡單疊加,而是深刻互動和理解。快系統從慢系統的輸出中學習,并形成長期記憶;慢系統從快系統的輸入中獲得專業判斷和背景。
上述系統不僅適用于圖像識別,我們還嘗試把將其應用于自然語言生成,讓這樣一個通專融合架構生成非常專業化的描述文字,例如某種疾病治療方法、具體商品的營銷策略等。
我們發現,專業模型承擔了大部分任務。如下圖所示,藍色部分是專業模型生成的,紅色部分則是專業模型“求助”通用模型進行泛化推理之后產生的。80%的內容由專業模型獨立完成,而20%的慢推理對提升專業模型的泛化性有非常大的幫助(cogenesis: a framework collaborating large and small language models for secure context-aware instruction following. 2024)。
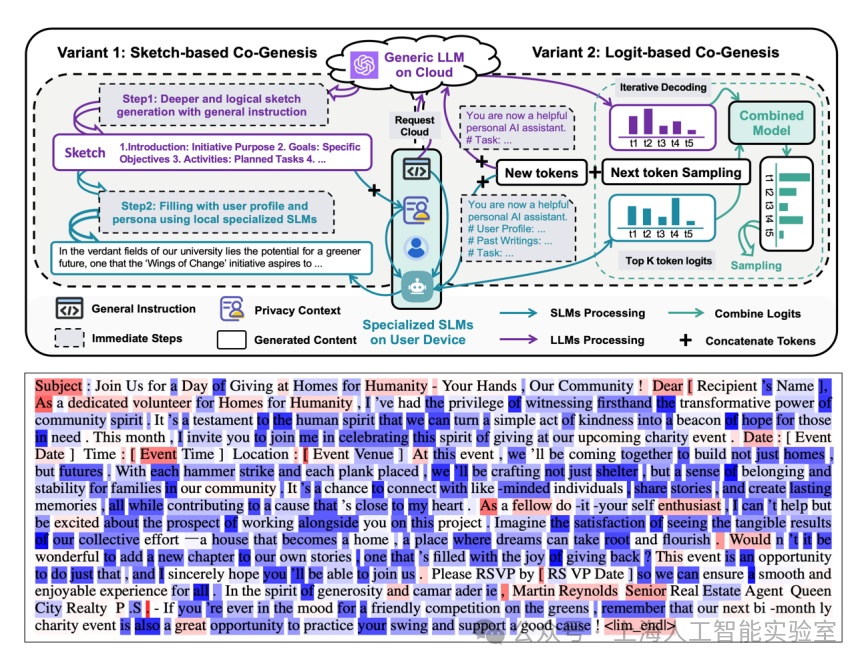
針對專業化個性內容生成任務,通用大模型僅對其中約20%的內容有貢獻(綱要內容/推理能力,紅色token),剩下80%內容則主要依賴專業化小模型生成(藍色token)
3、探索進化層
正如前面提到,人類學會游泳必須與真實物理世界互動,ai也是如此。在這一層,我們嘗試進行模型與環境長期實時交互,并進行具身自主探索與世界模型構建。比如上海人工智能實驗室提出了開源且通用的自動駕駛視頻預測模型genad,類似于自動駕駛領域的“sora”,能夠根據一張照片的輸入,生成后續高質量、連續、多樣化、符合物理世界規律的未來世界預測,并可泛化到任意駕駛場景,被多種駕駛行為操控。在與物理世界的互動探索中,一方面我們深入物理世界,另一方面則在虛擬世界中通過模擬進一步提升效率。如具身智能訓練,我們實現了在單卡上模擬訓練一小時,相當于在真實物理世界訓練380天的效率。這些成果通過首個城市級具身智能仿真訓練場浦源·桃源進行了開放,歡迎大家在這個平臺上訓練專屬的具身智能。

通專融合實踐:科學發現
2023年1月5日《nature》發表的封面文章《papers and patents are becoming less disruptive over time》,文章提到,過去70年來論文數越來越多,專利數越來越多,但單篇論文的影響力卻逐年下降,這不僅僅出現在計算機領域,也適用于生物、物理、化學等領域。
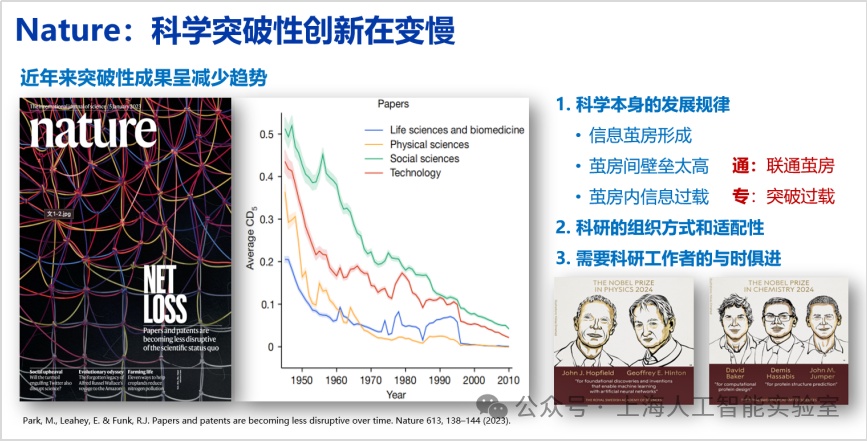
這篇論文只做了數據分析,沒有追溯原因。對此我的個人思考是,該現象與科學發展規律密切相關。科學經過100余年的建設,已建成趨于完美的大廈,在大廈內部,每門子學科形成了非常強大的信息繭房,繭房間壁壘高,繭房內信息過載,所以導致論文與以前相比很難產生更廣泛的影響力。解決這一問題,還需要對科研的組織方式和適配性進行適當調整。與此同時,也需要科研工作者與時俱進,用好ai新工具。我們有沒有可能通過人工智能在技術層面幫助科學家獲得更多突破?例如,人工智能的通用能力可以幫助人類解決信息壁壘太高的問題——因為人類的信息容量是有天花板的。繭房的信息過載的問題,則可以通過人工智能系統深度思考突破。
所以,通專融合是解決科學創新,開創下一代科學創新范式必須具備的能力。關于使用大模型開展科學創新,目前存在諸多問題,例如不確定性和幻覺。不過原openai聯合創始人andrej karpathy認為,這種不確定和幻覺一方面可以被認為是大模型目前的不足,但另一方面則更像一個特性而非缺陷,這種幻覺與創造性相關,模型的幻覺可以與人類做夢類比。在科學歷史上,德國有機化學家august kekul夢見銜尾蛇,進而發現苯環結構。這種發現的過程,從某種意義上講,與大模型的幻覺具有很強的相似性,關鍵在于如何把幻覺的創造性用好,利用大模型的這種特點發揮價值。基于這些思路,我們過去幾年來開展了一系列的工作,比如我們認為大語言模型是非常有效的零樣本(zero-shot)科學假設的提出者。所謂零樣本就是大模型可以提出全新、原創的科學假設。不一定像牛頓三大運動定律那樣具有劃時代意義,但模型確實能提出一些科學家沒有發現和觀察到的現象(如我們2023年的工作large language models are zero shot hypothesis proposers以及近期工作ultramedical: building specialized generalists in biomedicine)。例如,我們構建的全自動蛋白質組學知識發現系統proteus能結合真實的蛋白質組學數據,獨立發現了191條經過專家評估的、具有自洽性、邏輯性和創新性的科學假設(https://arxiv.org/abs/2411.03743)。
在相關的工作中,我們驗證了通專融合大模型能夠提出有效的科學假設。如果把通專融合再進一步延伸至多智能體,我們發現,具備通專融合的系統,可以在科學研究的全生命周期過程中發揮不同的作用,并可與人類科學家進行配合。
我們進而提出了“人在環路大模型多智能體與工具協同”概念框架,用以模仿人類科研過程。通過構建ai分析師、工程師、科學家和批判家等多種角色,同時接入工具調用能力來協同提出新的假設,并進一步將人類專家納入其中,借助“人在環路”挖掘人機協同的潛力。實驗結果表明,這一框架能夠顯著提升假設發現的新穎性與相關性等多個維度指標(large language models are zero shot hypothesis proposers. neurips 2023,https://arxiv.org/abs/2311.05965)。
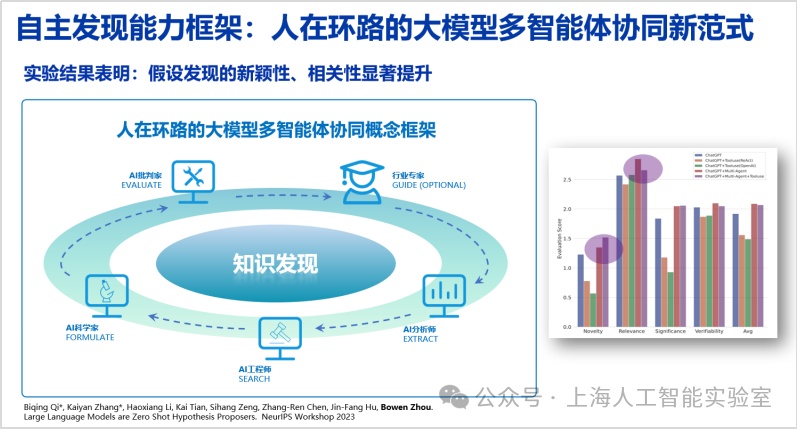
早在1900年,德國數學家大衛·希爾伯特(david hilbert)提出了著名的“23個問題”,引領了數學多個子領域數百年的發展。無論是希爾伯特還是愛因斯坦,他們都談到過,提出科學問題,遠比解決問題更重要。我們希望通專融合的ai系統,能幫助各個領域出現更多希爾伯特。

展望:agi的中心法則?
分子生物學中,有一個被稱為“中心法則”的概念,1958年由諾貝爾獎得主佛朗西斯·克里克(francis crick)首次提出,明確了遺傳信息從dna傳遞到rna,再從rna傳遞到蛋白質的過程。這一法則不僅深刻揭示了生命現象的本質,也為之后的生物技術發展提供了方向指導。隨著科學研究的深入,中心法則經歷了多次修正和完善,逐漸成為分子生物學的核心理論之一。
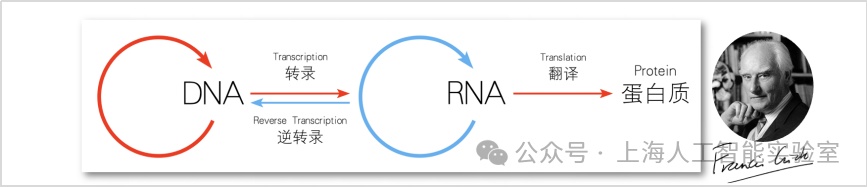
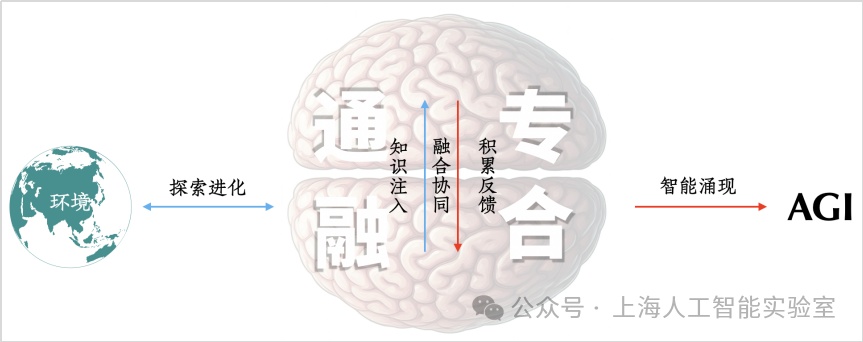
這一法則令我印象深刻。因為它非常有洞察地揭示和影響著生物領域的各個方面。這進一步引發了我的聯想:關于agi如何實現,此前還未形成一條指導實踐的完整路徑,我們能否找到一種agi的“中心法則”?我在報告中提出的“通專融合”路徑,是對這一問題的探索。生物學的中心法則是在幾十年研究中不斷地迭代更新,很多優秀科學家一同共創,做出了杰出貢獻。同理,agi可能也需要這樣來自人工智能研究與其他交叉學科社區的共創。